
Federated Stream Processing
Medusa is part of the SLAM project.
Overview
There is a large class of emerging applications in which data,
generated in a distributed environment, is pushed asynchronously to
servers for processing. Some example applications for which this
``push'' model for data processing is appropriate include financial
services (e.g., price feeds), asset-tracking services (e.g., reporting
the status of objects and equipment in real-time), fabrication line
management (e.g., real-time monitoring and control of manufacturing
systems), network management (e.g., intrusion detection), medical
applications (e.g., monitoring devices and sensors attached to
patients), environmental sensor/actuator systems (e.g., climate,
traffic, building, bridge monitoring), and military applications
(e.g., missile or target detection).
Several research projects currently focus on building novel
stream-processing engines that are better suited to support this new
class of applications than classic data-management systems. Some of
these projects are
Aurora,
STREAM,
TelegraphCQ.
and Cougar,
Early efforts in stream-oriented processing
have focused on designing new operators and new languages, as well as
building high-performance engines operating at a single site. More
recently, the attention has shifted toward extending these engines to
distributed environments. The latter is the focus of Medusa.
Medusa is a distributed stream-processing system built using Aurora as the
single-site processing engine. Medusa takes Aurora queries and
distributes them across multiple nodes. These nodes can all be under
the control of one entity or can be organized as a loosely coupled
federation under the control of different autonomous participants.
A distributed stream-processing system such as Medusa offers several benefits:
- It allows stream processing to be incrementally scaled
over multiple nodes.
- It enables high-availability because the processing nodes can
monitor and take over for each other when failures occur.
- It allows the composition of stream feeds from different
participants to produce end-to-end services, and to take advantage
from the distribution inherent in many stream processing applications
(e.g., climate monitoring, financial analysis, etc.).
- It allows participants to cope with load spikes without
individually having to maintain and administer the computing, network,
and storage resources required for peak operation. When organized as a
loosely coupled federated system, load movements between participants
based on pre-defined contracts can significantly improve performance.
In Medusa we thus focus on distributed stream processing. We
investigate in particular load management and high availability
issues. We also take into consideration participant autonomy focusing
on schemes that apply to loosely coupled federated environments. To
promote positive interactions in such environments, Medusa relies on
economic principles to regulate participant collaborations and solve
the hard problems concerning load management and sharing.
Stream Processing
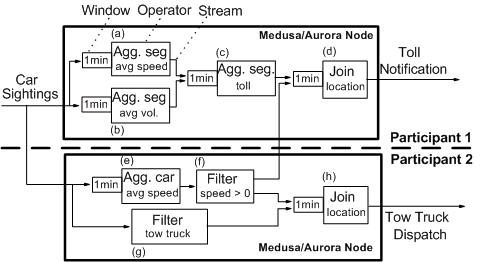 Figure 1: Example of distributed query.
Figure 1: Example of distributed query.
In stream-processing applications, data streams produced by
sensors or other data sources are composed and aggregated by
operators to produce some output of interest. A data stream
is a continuous sequence of attribute-value tuples that all conform to
some pre-defined schema (sequence of typed attributes). Operators are
functions that transform one or more input streams into one or more
output streams. A loop-free, directed graph of operators is called a
query network and all queries are continuous,
because they continuously processes tuples pushed on their input
streams.
Figure 1 shows an example of Medusa/Aurora query using a subset of the
Aurora operators. The query takes a stream of ``car sightings'' as
input, and produces streams of ``toll notifications'' and ``tow truck
dispatch''. The query first applies two windowed aggregate
operators to compute the average speed (a) and traffic volume (b) on
each segment of road, every minute. These values are then used to
compute tolls on these segments (c). Toll values are in turn
joined (d) with car locations to produce toll notifications
to these cars. Only cars whose speed is greater than zero (e and f)
are billed. The query also filters (g) cars identified as tow
trucks and joins (h) them, on the location field, with cars
that have broken down.
Medusa System Architecture
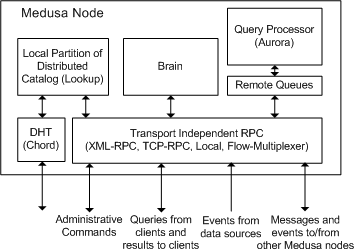 Figure 2: Medusa node software architecture.
Figure 2: Medusa node software architecture.
Figure 2 shows the software structure of a Medusa node. There are
two components in addition to the Aurora query processor. The Lookup
component is a client of an inter-node distributed catalog that holds
information on streams, schemas, and queries running in the
system. The Brain handles definitions of new schemas or streams and
handles query setup operations. Brain components at different nodes
communicate with each other to re-allocate queries and improve load
distribution. To do so, each Brain monitors local load using
information about the queues (IOQueues) feeding Aurora. It also uses
statistics on individual box load provided by Aurora. The Brain uses
this information to take autonomous and selfish load balancing
decisions that converge to good overall load distribution. Brain also
handles failure recovery. When a node detects a failure, it informs a
pre-assigned secondary, which takes over all queries and tuple
forwarding that were previously under the responsibility of the failed
node.
To move operators with a relatively low effort and overhead compared
to full-blown process migration, Medusa participants use remote
definitions. A remote definition maps an operator defined at a node
on to an operator defined at another. At runtime, when a path of
operators in the boxes-and-arrows diagram needs to be moved to another
node, all that's required is for the corresponding operators to be
instantiated remotely and for the incoming streams to be diverted to
the appropriately named inputs on the new node.
Load Management
Medusa employs an agoric system model to create incentives for
autonomous participants to handle each others load. Clients outside
the system pay Medusa participants for processing their queries and
Medusa participants pay each other to handle load. Payments and load
movements are based on pairwise contracts negotiated offline between
participants. These contracts set tightly bounded prices for migrating
each unit of load and specify the set of tasks that each participant
is willing to execute on behalf of its partner. Our mechanism, called
the bounded-price mechanism, gives participants tight control over
their choice of partners, the acceptable range of unit-prices for
load, and the set of tasks that can be shed or accepted. It also
achieves a low runtime overhead by bounding prices throu gh offline
negotiations.
High Availability
In collaboration with members of the Aurora team, we are exploring the
runtime overhead and recovery time tradeoffs between different
approaches to achieve high-availability (HA) in distributed stream
processing. These approaches range from classical Tandem-style
process-pairs to using upstream nodes in the processing flow as backup
for their downstream neighbors. Different approaches also provide
different recovery semantics where either some tuples are lost, some
tuples are re-processed, or operations take-over precisely where the
failure happened. We discuss these algorithms in more detail in the
technical report below. An important HA goal for the future is
handling network partitions in addition to individual node failures.
A more detailed overview of Medusa is available here: Medusa overview. Even more details are in
the papers and technical reports below. The figure below illustrates a
distributed Medusa system.
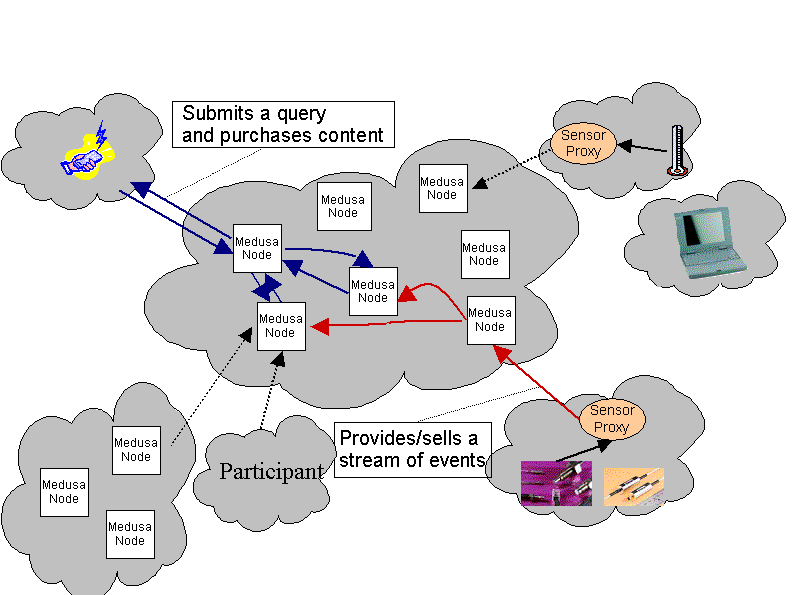 Figure 3: Example of federated Medusa deployment.
Figure 3: Example of federated Medusa deployment.
Papers and Technical Reports
-
Fault-Tolerance in the Borealis Distributed Stream Processing System
Magdalena Balazinska, Hari Balakrishnan, Samuel Madden, and Michael Stonebraker
To appear in SIGMOD 2005.
-
High-Availability Algorithms for Distributed Stream Processing
Jeong-Hyon Hwang, Magdalena Balazinska, Alexander Rasin,
Ugur Cetintemel, Michael Stonebraker, and Stan Zdonik
The 21st International Conference on Data Engineering. ICDE 2005
-
Contract-Based Load Management in Federated Distributed Systems
Magdalena Balazinska, Hari Balakrishnan, and Mike Stonebraker
1st Symposium on Networked Systems Design and Implementation (NSDI)
San Francisco, CA, March 2004.
-
A Comparison of Stream-Oriented High-Availability Algorithms
Jeong-Hyon Hwang, Magdalena Balazinska, Alexander Rasin,
Ugur Cetintemel, Michael Stonebraker, and Stan Zdonik
Technical Report CS-03-17. Brown University, September 2003.
-
The Aurora and Medusa Projects
Stan Zdonik, Michael Stonebraker, Mitch Cherniack, Ugur Cetintemel,
Magdalena Balazinska, and Hari Balakrishnan
Bulletin of the Technical Committe on Data Engineering
IEEE Computer Society. March 2003. p.3-10. (Invited Paper).
-
Scalable Distributed Stream Processing
Mitch Cherniack, Hari Balakrishnan, Magdalena Balazinska,
Don Carney, Ugur Cetintemel, Ying Xing, and Stan Zdonik
CIDR 2003 - First Biennial Conference on Innovative Data Systems Research,
Asilomar, California, January 2003.
Theses
-
Richard Tibbetts
Linear Road: Benchmarking Stream-Based Data Management Systems
M. Eng. Thesis, Massachusetts Institute of Technology, August 2003.
[Postscript (1.3 MB)]
[.ps.gz (563 KB)]
[PDF (631 KB)](61 pages)
-
Hiroyoshi Iwashima
Differential Bandwidth Allocation with Multiplexed TCP Connections
M. Eng. Thesis, Massachusetts Institute of Technology, August 2003.
[Postscript (1 MB)]
[.ps.gz (250 KB)]
[PDF (345 KB)](66 pages)
People
Faculty:
Graduate Students:
Alumni/ae:
- Hiroyoshi Iwashima
- Jon Salz
- Kwok Lee Tang
- Richard Tibbetts
Collaborations
The Medusa group collaborates with the Aurora project,
which is a collaboration between Brown
University, Brandeis
University and MIT.
M. I. T. Computer Science and Artificial Intelligence Laboratory · 32 Vassar Street · Cambridge, MA 02139 · USA
Last modified: Fri Oct 17 16:58:34 EDT 2003